10. An industry currently has 100 firms, each of which has fixed cost of $16 and average variable cost as follows: Quantity Average Variable Cost 1 $1 2 2 3 4 4 a. Compute a firm's marginal cost and average total cost for each quantity from 1 to 6. b. The equilibrium price is currently $10. How much does each firm produce? What is the total quantity supplied in the market? c. In the long run, firms can enter and exit the market, and all entrants have the same costs as above. As this market makes the transition to its long-run equilibrium, will the price rise or fall? Will the quantity demanded rise or fall? Will the quantity supplied by each firm rise or fall? Explain your answers.
10. An industry currently has 100 firms, each of which has fixed cost of $16 and average variable cost as follows: Quantity Average Variable Cost 1 $1 2 2 3 4 4 a. Compute a firm's marginal cost and average total cost for each quantity from 1 to 6. b. The equilibrium price is currently $10. How much does each firm produce? What is the total quantity supplied in the market? c. In the long run, firms can enter and exit the market, and all entrants have the same costs as above. As this market makes the transition to its long-run equilibrium, will the price rise or fall? Will the quantity demanded rise or fall? Will the quantity supplied by each firm rise or fall? Explain your answers.

Essentials of Economics (MindTap Course List)
8th Edition
ISBN:9781337091992
Author:N. Gregory Mankiw
Publisher:N. Gregory Mankiw
Chapter13: Firms In Competitive Markets
Section: Chapter Questions
Problem 10PA

Related questions
Question
100%
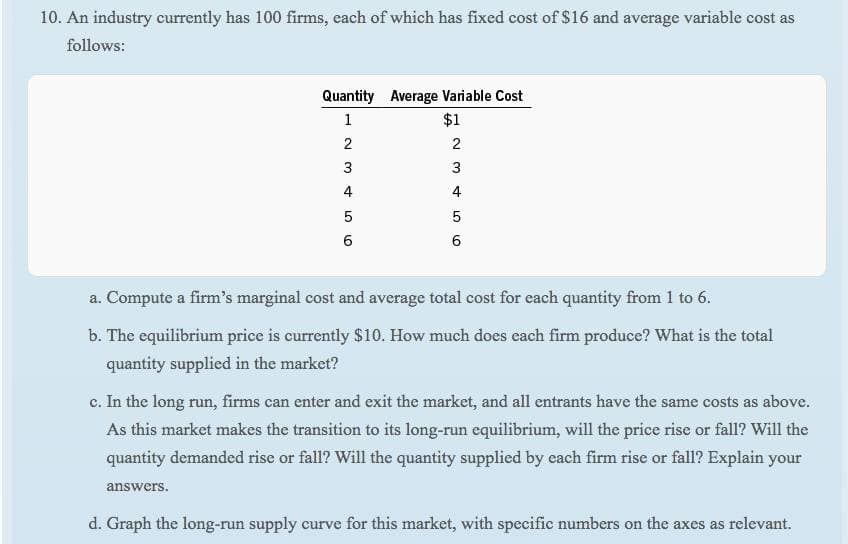
Transcribed Image Text:10. An industry currently has 100 firms, each of which has fixed cost of $16 and average variable cost as
follows:
TT
Quantity Average Variable Cost
1
$1
2
3
3
4
4
a. Compute a firm's marginal cost and average total cost for each quantity from 1 to 6.
b. The equilibrium price is currently $10. How much does each firm produce? What is the total
quantity supplied in the market?
c. In the long run, firms can enter and exit the market, and all entrants have the same costs as above.
As this market makes the transition to its long-run equilibrium, will the price rise or fall? Will the
quantity demanded rise or fall? Will the quantity supplied by each firm rise or fall? Explain your
answers.
d. Graph the long-run supply curve for this market, with specific numbers on the axes as relevant.
2.
Expert Solution
This question has been solved!
Explore an expertly crafted, step-by-step solution for a thorough understanding of key concepts.

This is a popular solution!

Trending now
This is a popular solution!

Step by step
Solved in 5 steps with 4 images

Knowledge Booster


Learn more about
Need a deep-dive on the concept behind this application? Look no further. Learn more about this topic, economics and related others by exploring similar questions and additional content below.Recommended textbooks for you
Essentials of Economics (MindTap Course List)
Economics
ISBN:
9781337091992
Author:
N. Gregory Mankiw
Publisher:
Cengage Learning

Principles of Economics 2e
Economics
ISBN:
9781947172364
Author:
Steven A. Greenlaw; David Shapiro
Publisher:
OpenStax

Principles of Economics (MindTap Course List)
Economics
ISBN:
9781305585126
Author:
N. Gregory Mankiw
Publisher:
Cengage Learning
Essentials of Economics (MindTap Course List)
Economics
ISBN:
9781337091992
Author:
N. Gregory Mankiw
Publisher:
Cengage Learning
Principles of Economics 2e
Economics
ISBN:
9781947172364
Author:
Steven A. Greenlaw; David Shapiro
Publisher:
OpenStax
Principles of Economics (MindTap Course List)
Economics
ISBN:
9781305585126
Author:
N. Gregory Mankiw
Publisher:
Cengage Learning

Principles of Economics, 7th Edition (MindTap Cou…
Economics
ISBN:
9781285165875
Author:
N. Gregory Mankiw
Publisher:
Cengage Learning

Principles of Microeconomics (MindTap Course List)
Economics
ISBN:
9781305971493
Author:
N. Gregory Mankiw
Publisher:
Cengage Learning
