
Concept explainers
Videos
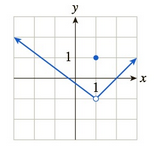
In Exercises 35–48 the graph of f is given. Use the graph to compute the quantities asked for. [HINT: See Examples 4–5.]
a.
b.
c.
d.
e.
f.
Want to see the full answer?
Check out a sample textbook solution
Chapter 10 Solutions
Finite Mathematics and Applied Calculus (MindTap Course List)


- (b) If we keep the first part of the hypothesis of Theorem 5.3.6(L’Hospital’s Rule) the same but we assume that lim f'(x)/g'(x) = ∞, x→a does it necessarily follow that lim f(x)/g(x)= ∞?, x→aarrow_forwardIn Exercises 15 and 16, use the formal definition of limit to prove that the function has a continuous extension to the given value of x.arrow_forwardGive a complete ?, ? proof of lim ?→3(4? − 5) = 7 That is, given ? > 0 find ? (as a function of ?) such that |?(?) − ?| < ? when |? − ?| < ?.arrow_forward
- Using the ε − N definition of a limit, prove that lim(n→∞)=(6n^3 −2n+1)/(2n^3+1)=3. The expert missed the first part of the question which asks for the ε − N definition.arrow_forwardLet ƒ(x) = x^(1/(1-x)). a. Make tables of values of ƒ at values of x that approach c = 1 from above and below. Does ƒ appear to have a limit as x--> 1? If so, what is it? If not, why not? b. Support your conclusions in part (a) by graphing ƒ near c = 1arrow_forwardInvestigate the limit numerically and graphically. lim?→±∞8?+14?2+9‾‾‾‾‾‾‾‾√limx→±∞8x+14x2+9 Calculate the values of ?(?)=8?+14?2+9‾‾‾‾‾‾‾‾√f(x)=8x+14x2+9 for ?=±100,x=±100, ±500,±500, ±1000,±1000, and ±10000.and ±10000. (Use decimal notation. Give your answers to six decimal places.) ?(−100)=f(−100)= ?(−500)=f(−500)= ?(−1000)=f(−1000)= ?(−10000)=f(−10000)= ?(100)=f(100)= ?(500)=f(500)= ?(1000)=f(1000)= ?(10000)=f(10000)= Graph ?(?)f(x) using the graphing utility. ?(?)=f(x)= 8x+1√4x2+9 powered by What are the horizontal asymptotes of ??of f? (Give your answer as a comma‑separated list of equations. Express numbers in exact form. Use symbolic notation and fractions where needed.) horizontal asymptote(s):arrow_forward
- Find the following limits when they exist: 1. lim g(x) x to 3+arrow_forwardIn some cases, numerical investigations can be misleading. Plot f (x) = cos π x . (a) Does lim x→0 f (x) exist? (b) Show, by evaluating f (x) at x = ±12 ,±14 ,±16 , . . . , that you might be able to trick your friends into believing that the limit exists and is equal to L = 1. (c) Which sequence of evaluations might trick them into believing that the limit is L = −1.arrow_forwardFind the value of the postive constant c, such that lim x->infinty ((x-c)/(x+c))^x=1/4arrow_forward
- What does the following table suggest about lim f (x) and lim f (x )? x ➔1- x ➔1+ x 0.9 0.99 0.999 1.001 1.01 1.1 f(x) 7 25 4317 3.00011 3.0047 3.0126arrow_forwardEvaluate the following limits lim as h approaches 0 (h-2)^2-4/2h lim as n approaches infinity sigma i=1 with n on top (i^2+3i-2/n^3)arrow_forwardsuppose f,g an d h are functions which g(x)<=f(x) <=h(x) ,for all x in an open interval containing a , except possibly at a. if lim g(x) ,x approaches to a does not exist or lim h(x) ,x approaches to a does not exist , will the lim f(x) ,x approaches to a do or does not exist ?arrow_forward
 Algebra & Trigonometry with Analytic GeometryAlgebraISBN:9781133382119Author:SwokowskiPublisher:Cengage
Algebra & Trigonometry with Analytic GeometryAlgebraISBN:9781133382119Author:SwokowskiPublisher:Cengage