Find the equation of the tangent plane and the normal line to the given surface at the specified point. 40/ry7 n(y) Point: (16, 1, 160) (a) Equation of tangent plane. Be sure to enter an equaiotn. (b) Equation of normal line. You will need to express your answer with symmetric equations but in two parts. (i) Symmetric equations with and y: and z (ii) Symmetric equations with
Find the equation of the tangent plane and the normal line to the given surface at the specified point. 40/ry7 n(y) Point: (16, 1, 160) (a) Equation of tangent plane. Be sure to enter an equaiotn. (b) Equation of normal line. You will need to express your answer with symmetric equations but in two parts. (i) Symmetric equations with and y: and z (ii) Symmetric equations with

Algebra & Trigonometry with Analytic Geometry
13th Edition
ISBN:9781133382119
Author:Swokowski
Publisher:Swokowski
Chapter3: Functions And Graphs
Section3.3: Lines
Problem 21E

Related questions
Question
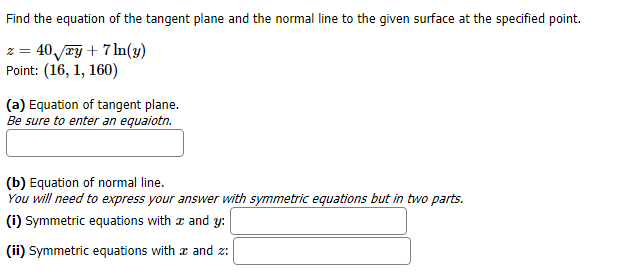
Transcribed Image Text:Find the equation of the tangent plane and the normal line to the given surface at the specified point.
40/ry7 n(y)
Point: (16, 1, 160)
(a) Equation of tangent plane.
Be sure to enter an equaiotn.
(b) Equation of normal line.
You will need to express your answer with symmetric equations but in two parts.
(i) Symmetric equations with
and y:
and z
(ii) Symmetric equations with
Expert Solution
This question has been solved!
Explore an expertly crafted, step-by-step solution for a thorough understanding of key concepts.

This is a popular solution!

Trending now
This is a popular solution!

Step by step
Solved in 4 steps with 3 images

Recommended textbooks for you
Algebra & Trigonometry with Analytic Geometry
Algebra
ISBN:
9781133382119
Author:
Swokowski
Publisher:
Cengage

Trigonometry (MindTap Course List)
Trigonometry
ISBN:
9781337278461
Author:
Ron Larson
Publisher:
Cengage Learning

Functions and Change: A Modeling Approach to Coll…
Algebra
ISBN:
9781337111348
Author:
Bruce Crauder, Benny Evans, Alan Noell
Publisher:
Cengage Learning
Algebra & Trigonometry with Analytic Geometry
Algebra
ISBN:
9781133382119
Author:
Swokowski
Publisher:
Cengage
Trigonometry (MindTap Course List)
Trigonometry
ISBN:
9781337278461
Author:
Ron Larson
Publisher:
Cengage Learning
Functions and Change: A Modeling Approach to Coll…
Algebra
ISBN:
9781337111348
Author:
Bruce Crauder, Benny Evans, Alan Noell
Publisher:
Cengage Learning