8- In the following circuit find i() 2Ω 0

Introductory Circuit Analysis (13th Edition)
13th Edition
ISBN:9780133923605
Author:Robert L. Boylestad
Publisher:Robert L. Boylestad
Chapter1: Introduction
Section: Chapter Questions
Problem 1P: Visit your local library (at school or home) and describe the extent to which it provides literature...

Related questions
Question
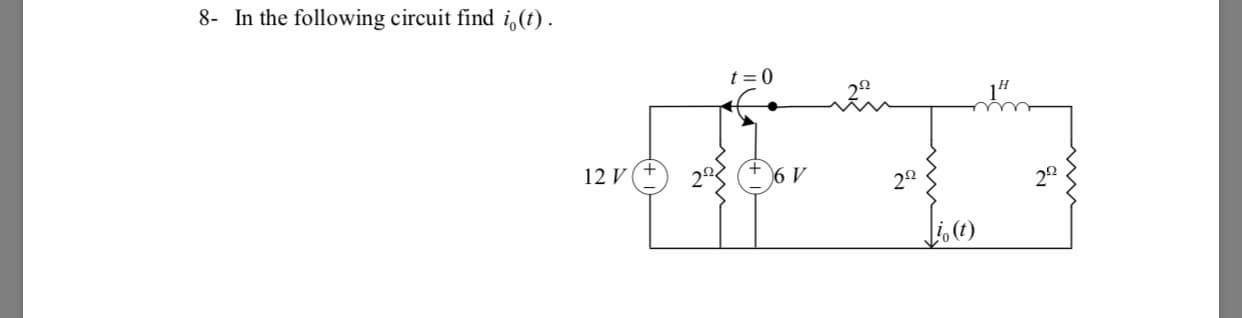
Transcribed Image Text:8- In the following circuit find i()
2Ω
0
Expert Solution


Trending now
This is a popular solution!

Step by step
Solved in 9 steps with 9 images

Recommended textbooks for you
Introductory Circuit Analysis (13th Edition)
Electrical Engineering
ISBN:
9780133923605
Author:
Robert L. Boylestad
Publisher:
PEARSON

Delmar's Standard Textbook Of Electricity
Electrical Engineering
ISBN:
9781337900348
Author:
Stephen L. Herman
Publisher:
Cengage Learning

Programmable Logic Controllers
Electrical Engineering
ISBN:
9780073373843
Author:
Frank D. Petruzella
Publisher:
McGraw-Hill Education
Introductory Circuit Analysis (13th Edition)
Electrical Engineering
ISBN:
9780133923605
Author:
Robert L. Boylestad
Publisher:
PEARSON
Delmar's Standard Textbook Of Electricity
Electrical Engineering
ISBN:
9781337900348
Author:
Stephen L. Herman
Publisher:
Cengage Learning
Programmable Logic Controllers
Electrical Engineering
ISBN:
9780073373843
Author:
Frank D. Petruzella
Publisher:
McGraw-Hill Education

Fundamentals of Electric Circuits
Electrical Engineering
ISBN:
9780078028229
Author:
Charles K Alexander, Matthew Sadiku
Publisher:
McGraw-Hill Education

Electric Circuits. (11th Edition)
Electrical Engineering
ISBN:
9780134746968
Author:
James W. Nilsson, Susan Riedel
Publisher:
PEARSON

Engineering Electromagnetics
Electrical Engineering
ISBN:
9780078028151
Author:
Hayt, William H. (william Hart), Jr, BUCK, John A.
Publisher:
Mcgraw-hill Education,