Given an unlabeled dataset {x(1),...,x(m)}. The K-mean algorithm has been run with 40 different random initializations, and 40 different clusterings of the data have been Ex0 – µwl² to choose the best obtained. Describe how we should use m m clustering.

Q: What kind of repercussions may the proliferation of artificial intelligence and robots have in terms…
A: Artificial Intelligence (AI) is defined as a branch of computer science that focuses on creating…
Q: Problem#1 The following neural network is described in the class notes. x₁ -0.1 O x₂ = 0.2…
A: Define the input values and weights as TensorFlow constants. Define the computation graph with…
Q: Write a program to implement the decision tree learning algorithm using information gain as the…
A: Load the training data from a CSV file using the pandas library. Define a Node class to represent a…
Q: When a temperature sensor surpasses a threshold, your local nuclear power facility alarms. Core…
A: The control of temperature in nuclear power facilities is crucial for ensuring safety and preventing…
Q: PEAS is the name of the place where robot football players go to work.
A: PEAS in Context of AI In the field of Artificial Intelligence, PEAS stands for Performance Measure,…
Q: (Use SQL) The Car Maintenance team wants to learn how many times each car is used in every month and…
A: The following table is created using the given table structure and following DDL: CREATE TABLE…
Q: Mission: Write Python3 code to do binary classification. Data set: The Horse Colic dataset. You need…
A: KNN (K-Nearest Neighbors) is a non-parametric algorithm that can be used for binary classification…
Q: Problem 4 Suppose a data stream is { 1 0 1 1 0 0 1 00011001101100 }, which will be interleaved by a…
A: In digital communication systems, interleaving is a technique employed to improve the…
Q: Give specific justifications for why a certain model of machine learning is superior to others…
A: Machine learning models have advanced rapidly in recent years, with various architectures and…
Q: Explain one technological subject you know.
A: Machine Learning (ML) has become an increasingly important area of research and development in…
Q: What are invasive species, and what is the potential impact they have in new areas? When invasive…
A: Invasive species are non-native organisms that are introduced into a new ecosystem, often due to…
Q: Problem#1 Linear Regression The values of 2 variables X and Y are given below. Here X is the…
A: Define the data: input the values of x and y. Calculate the mean of x, y, x*y, and x^2. Calculate…
Q: Using the following dataset, using the k-nearest neighbor algorithm of the T(3,8,9) observation,…
A: given data set Observation x1 x2 x3 class 1 2 9 6 Yes 2 9 4 16 No 3 12 0 19 No 4 4 3 8…
Q: If you have the following function, and the transformations listed below have happened, what will…
A: The equation of a parabola is given by: y=ax-h2+k where focus of the parabola is a,0 The vertex of…
Q: 1
A: Need to construct the table for the given problem
Q: 1. Anscombe's quartet shows us that datasets with the same statistical characteristics (e.g., mean,…
A: Anscombe's quartet serves as a powerful reminder of the importance of data visualization in…
Q: You have a fundamental comprehension of the use of social networking sites. What are the benefits…
A: The core concept behind autonomous computing is the use of hardware and software systems that are…
Q: You are working as a data scientists and you have received data on house prices in the Boston…
A: Based on the provided instructions the model is built as shown below: import pandas as pdimport…
Q: The marketing department of a riding mower manufacturer wants to understand who are more likely to…
A: Entropy is a measure of the impurity or randomness of a dataset. It is commonly used as a metric to…
Q: Discuss the benefits and drawbacks of AI-supported online education in depth.
A: Artificial Intelligence (AI) is a broad field of computer science that involves developing machines…
Q: helor is not married t orge is a mathematicia
A: Using the given symbols, we can represent the three sentences as follows: A) ∀x (Mathematician(x)…
Q: t you expect the R output to be. Choose... Choose... Choose... Choose... O " O "
A: Given a data set x, the following commands have been run: library(cluster); agnes(x=X)->AG;…
Q: 9.Your venture incorporates the accompanying inquiries. 1) Propose two unique numeric inquiries that…
A: For this venture, I will propose two numeric questions related to two different classification…
Q: create a Power or intrest chart for the following Data using exel or google sheet or matlab wich…
A: A power/interest chart, also known as Stakeholder Map, is used to categorize certain stakeholders…
Q: a
A: Python using the NLTK library:
Q: Given the data set A = {0, 0, 12, 13, 14, 15, 16, 18, 22, 25, 30} the mean is , the median is ,…
A: In statistics, measures of central tendency are used to represent the "typical" or "average" value…
Q: You're social media-savvy. Explain autonomous and cloud computing. Examples demonstrate. Cloud…
A: Understanding the potential of the integration of self-management and cloud computing technology can…
Q: What does the percentile ranking tell us? Group of answer choices What percent of the data is below…
A: Percentile ranking is a statistical measure used to understand the relative position of a particular…
Q: In this section, we will compare and contrast an M2M-oriented approach with a Lo T-oriented strategy…
A: Understanding M2M and IoT Machine-to-Machine (M2M) communication and the Internet of Things (IoT)…
Q: P is a predicate, f, g are functions, a is a constant, and x, y, we have ➡), f(y, x), × ), and f(a,…
A: Given that P is a predicate, f, g are functions, a is a constant, and x, y, u, v, w are variables,…
Q: Match the following radical expressions to their corresponding exponential forms. 1.16 -2.1/5 3. Vy…
A: The relationship between the radical forms and exponential form is as follows: xba=xba Using this…
Q: 3. Suppose a deep neural network N is used for the image quality assessment problem. The input of…
A: Image quality assessment is a critical task in the field of computer vision and image processing, as…
Q: Explain what Machine Language is and what it does. Also, why can't technology understand the English…
A: Machine Language (also known as machine code or assembly language) is the lowest-level programming…
Q: aimed at monitoring potential illicit financial activities carried out by individuals. To accomplish…
A: Suppose you were responsible for a task aimed at monitoring potential illicit financial activities…
Q: Express universal quantification in terms of existential quantification
A: The phrase "for every x'' (or "for all x'') is called a universal quantifier and is denoted by ∀x.…
Q: Which of these most accurately describes the translation of the graph of y=(x-4)² + 1 to the graph…
A: The question asks about translating the graph of the quadratic function y = (x - 4)^2 + 1 to the…
Q: How is Phoenix able to remember the way to her destination? A. She is able to find her way with…
A: In Eudora Welty's "A Worn Path," the protagonist Phoenix Jackson embarks on a journey to obtain…
Q: Consider the data points shown in Figure 1. There are three clusters already formed. C1 = {a, c, f},…
A: Clustering is a crucial technique in data analysis, as it helps to identify meaningful groups within…
Q: How is PACS relate to IoT?
A: To PACS and IoT PACS, or Picture Archiving and Communication System, is a medical imaging technology…
Q: A neural network is built for a dataset that has binary target value (0 or 1). The cost function…
A: Import the TensorFlow library and disable version 2 behavior. Define the inputs for the neural…
Q: rasts (implemented using a statistical package) among the following nts to compare them: without…
A: Solution below
Q: find the value of each of the summary statistics. Men’s Heights (inches 71 64 71 70 70 72 70 76 68…
A: In this problem, we are given a list of men's heights in inches, and we are required to find the…
Q: When we discuss measures of center and spread, there are certain ones that go together, and certain…
A: In statistics, understanding both the central tendency and the spread of a dataset is crucial for…
Q: How can I learn more about what "AI" stands for?
A: AI stands for Artificial Intelligence, which refers to the development of computer systems that can…
Q: Lead Kampala's crimefighting. AI can learn these procedures to handle them.
A: The integration of AI technologies in crime fighting has the potential to transform law enforcement…
Q: Given code line, std::string un_address = "405 East 42nd Street, New York, NY, 10017"; Fill in the…
A: C++ is a high-level programming language widely used for developing system software, device drivers,…
Q: Describe the differences between L1 and L2 regularization. Explain how each technique affects the…
A: Regularization techniques are essential in machine learning and deep learning to prevent overfitting…
Q: computing offers a number of benefits over in-house server and network administration
A: Yes, that is correct. Cloud computing offers several benefits over traditional in-house server and…
Q: Suppose X|Y=1 is a Uniform(0,4) density, X|Y=0 is a Uniform(2,6) density, and P(Y=1) = 2/3.…
A: Solution: From the given information,
Q: 3
A: Given information: It is given that any subset E⊂S is contained in ∪s∈E(s].
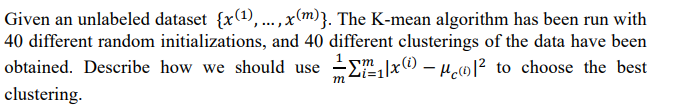

Step by step
Solved in 3 steps
