Let's consider the following 3-state MDP(Markov Decision Process) for a robot trying to walk, the three states being 'Fallen', 'Standing' and 'Moving', as shown in the following figure. 1, +1 1, +1 Standing 0.6, +2 0.4, +1 0.4, -1 Moving Fallen 0.2, -1 0.8, +2 0.6, -1 slow action (black) fast action (green) Use the MDP formulation to code the following problem and find the optimal Values using the value iteration algorithm. And then use policy iteration method to find optimal policy for discount factor y=0.1. Try using this method with a different discount factor, for example a much larger discount factor like 0.9 or 0.99, or a much smaller one like 0.01. Does the optimal policy change comment on it?
Let's consider the following 3-state MDP(Markov Decision Process) for a robot trying to walk, the three states being 'Fallen', 'Standing' and 'Moving', as shown in the following figure. 1, +1 1, +1 Standing 0.6, +2 0.4, +1 0.4, -1 Moving Fallen 0.2, -1 0.8, +2 0.6, -1 slow action (black) fast action (green) Use the MDP formulation to code the following problem and find the optimal Values using the value iteration algorithm. And then use policy iteration method to find optimal policy for discount factor y=0.1. Try using this method with a different discount factor, for example a much larger discount factor like 0.9 or 0.99, or a much smaller one like 0.01. Does the optimal policy change comment on it?

Operations Research : Applications and Algorithms
4th Edition
ISBN:9780534380588
Author:Wayne L. Winston
Publisher:Wayne L. Winston
Chapter17: Markov Chains
Section: Chapter Questions
Problem 15RP

Related questions
Question
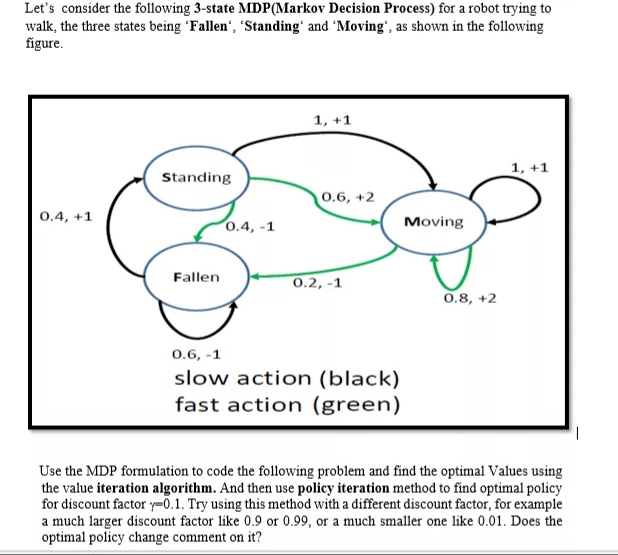
Transcribed Image Text:Let's consider the following 3-state MDP(Markov Decision Process) for a robot trying to
walk, the three states being 'Fallen“, 'Standingʻ and 'Moving', as shown in the following
figure.
1, +1
1, +1
Standing
0.6, +2
0.4, +1
0.4, -1
Moving
Fallen
0.2, -1
0.8, +2
0.6, -1
slow action (black)
fast action (green)
Use the MDP formulation to code the following problem and find the optimal Values using
the value iteration algorithm. And then use policy iteration method to find optimal policy
for discount factor y=0.1. Try using this method with a different discount factor, for example
a much larger discount factor like 0.9 or 0.99, or a much smaller one like 0.01. Does the
optimal policy change comment on it?
Expert Solution
This question has been solved!
Explore an expertly crafted, step-by-step solution for a thorough understanding of key concepts.

This is a popular solution!

Trending now
This is a popular solution!

Step by step
Solved in 2 steps with 19 images

Knowledge Booster


Learn more about
Need a deep-dive on the concept behind this application? Look no further. Learn more about this topic, computer-science and related others by exploring similar questions and additional content below.Recommended textbooks for you
Operations Research : Applications and Algorithms
Computer Science
ISBN:
9780534380588
Author:
Wayne L. Winston
Publisher:
Brooks Cole
Operations Research : Applications and Algorithms
Computer Science
ISBN:
9780534380588
Author:
Wayne L. Winston
Publisher:
Brooks Cole