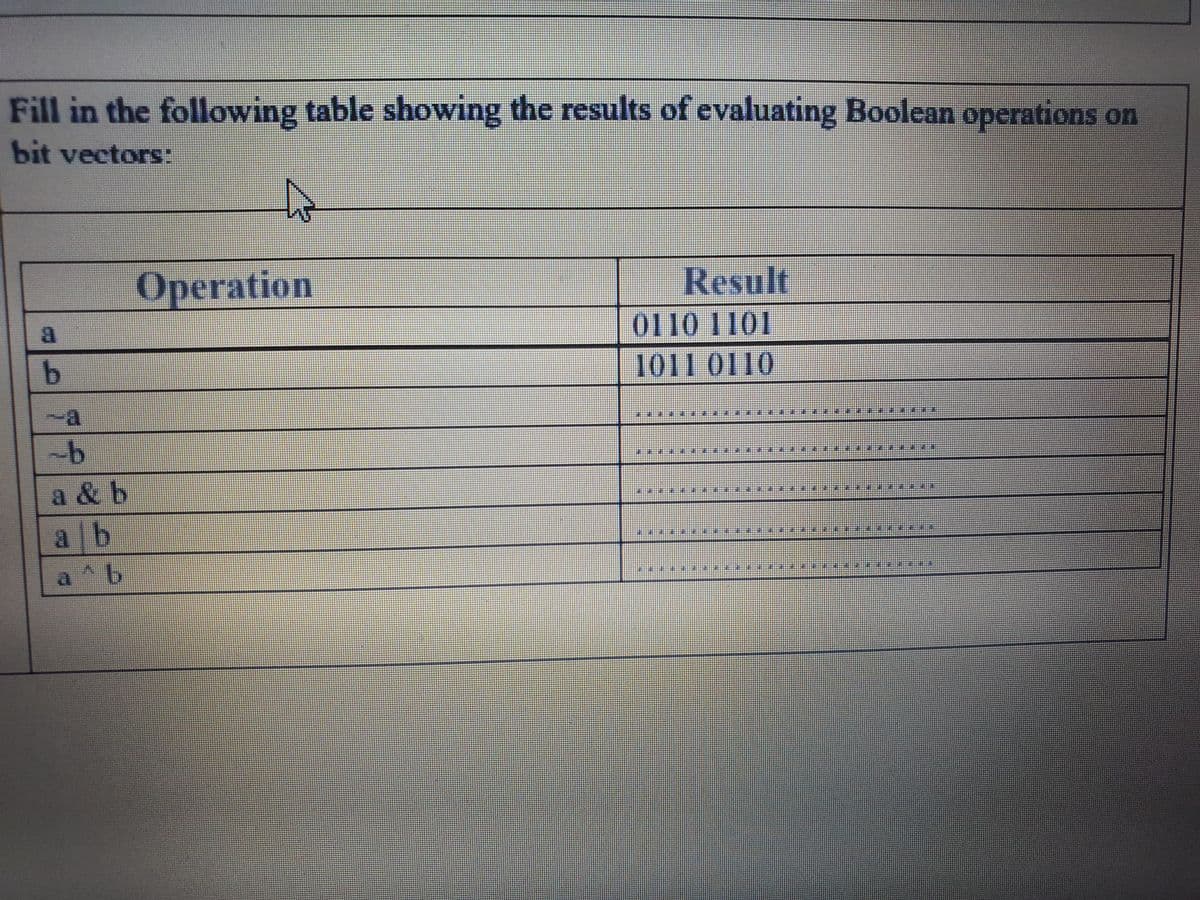
Fill in the following table showing the results of evaluating Boolean operations on bit vectors: Operation Result 0110 1101 1011 0110 -a a & b a b a ^b


Q: Fill in the following table showing the results of evaluating Boolean operations on bit vectors:…
A: Bitwise operators (also known as bit level programming) are used to manipulate data at the bit…
Q: Representing 7 bit floating -point Given that the: Sign: 1 bit (MSB) •Exponent: 3 bits •Mantissa:…
A: 261/16 => quotient=16 remainder=5 16/16 => quotient=1 remainder=0 1/16 =>…
Q: a) A digital sound recorder captures sound from the real-world, processes the audio and stores it in…
A: "Because of our bartleby policy, we need to solve one question at a time if you need the rest of…
Q: carry flag is used when the result of an arithmetic operation is equal to 8 bits O less than 8 bits…
A: Given: To choose the correct option.
Q: How is the number of redundant bits necessary for code related tothe number of data bits?
A: Some kind of redundancy is introduced in the system in order to get better reliability. The…
Q: Show Steps Please 18. If the floating-point number representation on a certain system has a sign…
A: The solution to the given question is: a) The Largest Positive 0.11112 x 23 = 111.12 = 7.5 The…
Q: 1. Write down the mathematical notation for fixed point representationand floating representation…
A: According to the information given:- We have to explain the fixed point representation and floating…
Q: Suppose a 32-bit data word stored in the main memory is 01010001 01100010 01011010 01000010. Using…
A:
Q: One's complement representations of integers is used to simplify computer arithmetic, while…
A: To get 1's complement of a decimal number first convert it to it's binary equivalent and then toggle…
Q: 157. One byte is the collection of a. 2-bits b. 4-bits c. 7-bits d. 8-bits
A: Given data:- One byte is the collection of a. 2-bits b. 4-bits c. 7-bits d. 8-bits
Q: Fill in the following table to show how the given integers are represented, assuming that 16 bits…
A: Convert the integer value to binary:For positive integer:Divide the integer number by 2. The integer…
Q: Fill in the following table to show how the given integers are represented, assuming that 16 bits…
A: Big endian machine: Big-end first data is stored, the lowest address contains biggest Little…
Q: Express the following double word (32 bits): Ox12345678 in (a) Big Endian format and (b) Little…
A: Answer: I have given answered in the handwritten format in brief explanation
Q: We reviewed bitwise logical operations in C (&=AND, |=OR, ^=XOR): A = 0011 1100 B = 0000…
A:
Q: Q. If 8 Bits are equals to 1 byte then how many bytes can be formed in 67464 Bits?
A: This question is related to computer architecture.
Q: Convert the following float-point decimal numbers into binary: A=0.05, B=-0.04375; and then, find…
A: According to the information given:- We have to convert floating point decimal to binary and find…
Q: Consider a 7-bit floating-poin representation based on IEEE floating-point format. This format does…
A: 2). 32/512 = 100000 x 2-9 = 1. 000 x 2-4 , So the fraction bits are 000 and exponent bits will be…
Q: 5) Add the following two pairs of 8-bit numbers, which are already in their 2's complement…
A:
Q: B) i. Represent the following two integers (2 bytes each using 2's complement) in computer memory…
A: We need to represent the given numbers in required notation.
Q: Consider a 16-bit binary floating point number representation system: + SE EE EEE m | m | m т т т т…
A:
Q: Convert each of the following values in our educational 14-bit biased floating-point representation…
A:
Q: For 10 bits floating point representation using: seeeefffff, what is the bias for denormalized…
A: Please give positive ratings for my efforts. Thanks. ANSWER Qstn 1 : Number of bits for…
Q: Q2 (а) Represent the following floating-point number in a 32-bit format. 0.000000000000001985 (b)…
A: Represent the following floating-point numbers into the 32-bit format. given number:…
Q: Using the smallest data size possible, either a byte, a halfword (16 bits), or a word (32 bits),…
A: Two's complement: a. -18304 Firstly, we find the binary of this number.
Q: Question 3. Use the 32-bit floating point representation to represent the following numbers in A (-…
A: It’s a datatype used to give us a close approximation to real (i.e., non-integer) numbers in…
Q: Express the value 0.3 in the 32-bit floating point format that we discussed in class today. Feel…
A: IEEE 32 BITS uses EXCESS 127 SIGN BIT EXPONENT MANTISSA 1 BIT 8 BITS 23 BITS…
Q: In this question, we consider a non-standard floating point number representation, which is based on…
A: NOTE: please correct the formula for bias : it is 2(exponent-1) - 1 , otherwise we cannot…
Q: Each of the following pairs of signed integers are stored in computer words (6 bits). Compute the…
A:
Q: Suppose we want an error-correcting code that will allow all single-bit errors to be corrected for…
A: According to the question, we have to find parity bits are necessary to an error-correcting code…
Q: What is the relationship between the number of redundant bits required for code and the number of…
A: Redundant bits Some kind of redundancy is introduced in the system in order to get better…
Q: A = signed (integer) 16 bit = &60 B = signed (integer) 16 bit = &70 D= signed (integer) 16 bit D=…
A: Lets see the solution.
Q: The advantage of the ____ code over pure binary numbers is that only one bit changes at a time when…
A: Filled the given statement
Q: Suppose we want an error-correcting code that will allow all single-bit errors to be corrected for…
A: A parity bit is a check bit that attach with binary data, its value is either 1 or 0 to make the…
Q: Complete the table below to show the numerical results from applying the indicated operation code to…
A: Solution: Given R=1 for Rotate R=0 for Shift D=1 for Right D=0 for Left F=fill and A2-A0 number of…
Q: One's complement representations of integers is used to simplify computer arithmetic, while…
A: The one's complement of a number is to invert binary bits from 1 => 0 and 0 => 1. The one's…
Q: (c) Using the smallest data size possible, either a byte (8 bits), a halfword (16 bits), or a word…
A: Introduction: In order to find out the 2s complement of any decimal number, we have to first convert…
Q: Complete the following table for a word size of 12 bits UMax (unsigned Max Value)…
A: In 2ʼs complement notation, the most significant bit indicates the sign bit, 0 for nonnegative and 1…
Q: QUESTION bits), convert the following values into two's complement representations: Using the…
A: To begin, determine the binary value of 20. As a result, the binary is (10100)2. This is a five-bit…
Q: 21. Suppose we want an error-correcting code that will allow all single-bit errors to be corrected…
A: As i have read guidelines i can provide answer of only 1 part of questions in case of multiple…
Q: Consider the following 10 bits floating point format. In this format 5 bits are reserved for the…
A: We need to answer questions based on floating point storage.
Q: Given the following decimal numbers, convert the numbers to a 16-bit memory location in binary using…
A: Given decimal numbers, 1659 -1659 9546 -9546
Q: Question 2: It is required to subtract the number (25) 10 from the number (11)16. Assume 8-bit…
A: Given Numbers: (25)10 = (00011001)2 (11)16 = (00010001)2 1. To subtract (25)10 from (11)16 in 1's…
Q: A _______ is made up of 8 ________. a. Bit, Bytes b. Byte, Bits c. Byte,…
A: A Byte is a data unit that comprises of 8 binary digits in most of the computer systems. In most of…
Q: inal Exam, Computer Organization 110408240, Sep 1 2021 Consider the following binary number that is…
A: Here in this question we have given a floating point number in which 1,8 ,8 format.and we have…
Q: 2. For a computer that uses 8-bit word size and Signed Magnitude (SM) arithmetic to represent…
A: a) To get a magnitude representation we need to divide the number with 2. 29 in sign magnitude…
Q: Consider a 5-bit two's complement representation. Fill in the empty boxes in the following table.…
A: Two's complement is a mathematical operation on binary numbers, and is an illustration of a radix…
Q: Q2 (a) Represent the following floating-point number in a 32-bit format. 0.000000000000001985 (b)…
A: Represent the following floating-point numbers into the 32-bit format. given number:…
Q: 5. We are using the simple model for floating point representation which is a 14-bit format, 5 bits…
A: We Are Using The Simple Model For Floating Point Representation Which Is A 14-Bit Format,
Q: Show Steps Please 19. Assume we are using the simple model for floating-point representation as…
A: Given that, the problem is assumed of using simple model for floating point representation.


Trending now
This is a popular solution!

Step by step
Solved in 2 steps



- Thank you but I need it without using vectorsPlease answer the "function" I already did the code. thank you this is my code : A = [2,1,0;-1,1,1;1,1,-1] [ss,li,bas] = splibas(A) function [ss,li,bas] = splibas(A) % Initialize outputs to false ss = false; li = false; bas = false; % Get Dimension of vectors dim = size(A(:,1),1); % Get number of vectors n = size(A,2); % Calculate Rank of A r= rank(A); % If rank is equal to number of vector % Vectors are linearly independent if(r==n) li = true; end % Calculate row echelon form of A RE = rref(A); % Find number of non-zero rows span = 0; for i=1:dim if(~isequal(RE(i,:),zeros(1,n))) span = span + 1; end end % If number of non-zero rows equals vector dimension % Vectors form a spanning set if(span==dim) ss = true; end % If vectors are both spanning set and linearly-independent % They form Basis if(ss==true && li==true) bas = true; end endCreate a MATLAB script file that solves matrices with the following conditions: a. Create a 10 x 5 vector M (range of vector numbers is from -100 to 100) b. Create a 10 x 5 vector N (range of vector numbers is from -100 to 100) c. Print on display M15 d. Print on display N24 e. Print on display fourth column f. Print on display the sum of vectors M and N
- in matlab Using the colon (:) operator, create the following row vectors. 9 7 5 3 1 3 4 5 6 7 8 1.3000 1.7000 2.1000 2.5000work and write the cosine function's taylor expansion (N=10) in C++ and compare the <cmath> with your version (see nartual exponent EXP() vs exp()). EQUATION ATTACHED. EXAMPLE: #include <iostream> #include <cmath> using namespace std; // lazy technique // Factorial Recursion. // https://en.wikipedia.org/wiki/Factorial // write the factorial function as a loop (iteration) // This might seem trivial, but people have researched this // this topic. Sterling series approximation // https://en.wikipedia.org/wiki/Stirling_approximation int fact(int N) { if (N == 0) return 1; else return N * fact(N - 1); } // taylor series approximation for the // natural exponent 2.718... which is abbreviated as exp. double EXP(double x) { double sum = 0.0; for (int i = 0; i < 10; i++) sum += pow(x, i) / fact(i); return sum; } // dummy--aka place holder--functions. double SIN(double x) { return 1; } double COS(double x) { return 0; } int main() { std::cout << "e-World!\n"; for…I need help on how to code this in matlab please. I tried watching tutorials on youtube and they were no help. A vector is given by X = [−3.5 −5 6.2 11 0 8.1 −9 0 3 −1 3 2.5] Using conditional statement and loops, develop a program that creates two vectors from X: Vector P contains all positive elements of X Vector N contains the negative elements of X. The elements in new vectors are in the same order as in X.
- In a letter to the editor of CACM, Rubin (1987) uses the following code segment as evidence that the readability of some code with gotos is better than the equivalent code without gotos. This code finds the first row of an n by n integer matrix named x that has nothing but zero values. for \( (i=1 ; i<=n ; i++)\{ \) for \( (j=1 ; j<=n ; j++) \) if \( (x[i][j] !=0) \) goto reject; println (First all-zero row Show Transcribed Text Rewrite this code without gotos either in C or Java. Compare the readability of your code to that of the example code. No hand written solution and no image[#165] Adding vectors |\vec{\textbf{A}}| = |\vec{\textbf{B}}| = |\vec{\textbf{C}}|∣A∣=∣B∣=∣C∣. Further, \vec{\textbf{A}} + \vec{\textbf{B}} + \vec{\textbf{C}} = 0A+B+C=0. What is the angle between \vec{\textbf{A}}A and \vec{\textbf{B}}B ?I need to check the following: first take two integer values let say x and y, multiply them (keep the product in new variable integerP) and check if multiplication caused overflow. Then take variable integerP and multiply it by 1 billion and check for overflow again. Make the same for float point values. In C language