
Related questions
details explanation and background
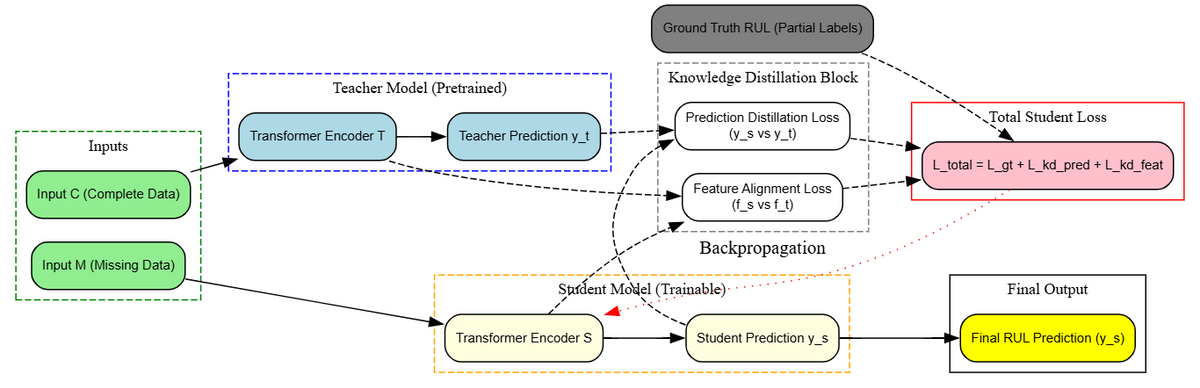
We solve this using a Teacher–Student knowledge distillation framework:
We train a Teacher model on a clean and complete dataset where both inputs and labels are available.
We then use that Teacher to teach two separate Student models:
Student A learns from incomplete input (some sensor values missing).
Student B learns from incomplete labels (RUL labels missing for some samples).
We use knowledge distillation to guide both students, even when labels are missing.
Why We Use Two Students
Student A handles Missing Input Features: It receives input with some features masked out. Since it cannot see the full input, we help it by transferring internal features (feature distillation) and predictions from the teacher.
Student B handles Missing RUL Labels: It receives full input but does not always have a ground-truth RUL label. We guide it using the predictions of the teacher model (prediction distillation).
Using two students allows each to specialize in solving one problem with a tailored learning strategy.
Detailed Explanation of the Teaching Process
1. Teacher Model (Trained First)
Input: Complete features
Label: Known RUL values
Output:
Final prediction ŷ_T (predicted RUL)
Internal features f_T (last encoder layer output)
2. Student A (Handles Missing Input)
Input: Some sensor values are masked
Label: RUL label available for some samples
Output: Predicted RUL: ŷ_S^A
How the Teacher Teaches Student A:
The student sees masked inputs. It tries to reconstruct what the teacher would have done if it had the full input.
We calculate:
Prediction distillation loss: How close is ŷ_S^A to ŷ_T?
Feature distillation loss: How close are the student’s encoder features to the teacher’s? f_S^A vs. f_T
Supervised loss: Where RUL label is available, compare to ground truth.
All these losses are combined, and we update the student encoder through backpropagation.
3. Student B (Handles Missing Labels)
Input: Full sensor data
Label: RUL label available only for some samples
Output: Predicted RUL: ŷ_S^B
How the Teacher Teaches Student B:
The student sees the full input, but no ground-truth RUL label.
We compute:
Prediction distillation loss: ŷ_S^B vs. ŷ_T
Supervised loss (only when RUL is available)
No feature distillation is used here — only predictions are used to guide learning.
Clarify Knowledge Distillation Process
Explain step-by-step how the teacher transfers knowledge to the student during training.
Use Two Distinct Strategies with Two Architectures
The student model handles two separate challenges
make a new diagram to illustrate the full work make sure sure to clarify explicitly the knowledge distillation part


Step by stepSolved in 2 steps


- hello please explain the architecture in the diagram below. thanks youarrow_forwardA problem-solving procedure that requires executing one or more comparison and branch instructions is called a(n) __________.arrow_forwardWhy is binary data representation and signaling the preferred method of computer hardware implementation?arrow_forward
- In a CPU, _______ arithmetic generally is easier to implement than _______ arithmetic because of a simpler data coding scheme and data manipulation circuitry.arrow_forward(Practice) You’re given the task of wiring and installing lights in your attic. Determine a set of subtasks to accomplish this task. (Hint: The first subtask is determining the placement of light fixtures.)arrow_forward
- Systems ArchitectureComputer ScienceISBN:9781305080195Author:Stephen D. BurdPublisher:Cengage Learning
 Principles of Information Systems (MindTap Course...Computer ScienceISBN:9781305971776Author:Ralph Stair, George ReynoldsPublisher:Cengage Learning
Principles of Information Systems (MindTap Course...Computer ScienceISBN:9781305971776Author:Ralph Stair, George ReynoldsPublisher:Cengage Learning Np Ms Office 365/Excel 2016 I NtermedComputer ScienceISBN:9781337508841Author:CareyPublisher:Cengage
Np Ms Office 365/Excel 2016 I NtermedComputer ScienceISBN:9781337508841Author:CareyPublisher:Cengage  Principles of Information Systems (MindTap Course...Computer ScienceISBN:9781285867168Author:Ralph Stair, George ReynoldsPublisher:Cengage Learning
Principles of Information Systems (MindTap Course...Computer ScienceISBN:9781285867168Author:Ralph Stair, George ReynoldsPublisher:Cengage Learning Information Technology Project ManagementComputer ScienceISBN:9781337101356Author:Kathy SchwalbePublisher:Cengage Learning
Information Technology Project ManagementComputer ScienceISBN:9781337101356Author:Kathy SchwalbePublisher:Cengage Learning