What are intermediate SQL concepts?
A query is a request for data or information from one or more database tables. This information could be presented in the form of pictorials, graphs, or complicated findings which helps in easy interpretation. Structured Query Language (SQL) is the most widely used programming language for retrieving and organizing data from relational databases. Collection of tables with rows and columns is referred to as a database. SQL is the language of databases. It makes it easier to extract specific data from databases, which can then be used for analysis.
What are the prerequisites and scope of intermediate SQL?
To apply intermediate SQL programming, one should be aware of some basic knowledge of SQL concerning the following:
- Database engines
- Concept of joins
- Environment setup
- Various tools for environment setup
Once the prerequisites are available, one can develop an intermediate database using various tools, keys, and functions for intermediate SQL programming.

MySQL is an open-source relational database management system. In a database management system, the use of various data types, aggregation functions, aggregation queries, unions, triggers, events, the use and creation of an index, etc., are done using intermediate SQL.
Database Engine
An SQL engine is a piece of software that identifies and interprets SQL commands to access and investigate data in a relational database. An SQL engine is sometimes known as an SQL query engine or an SQL database engine.
A storage engine and a query processor are two components of a common SQL server database engine design. The SQL engine is a database component that allows you to generate, read, update, and delete (CRUD) data. Different SQL engine architectures are supported by different SQL engine types. Businesses utilize SQL server database engines to create relational databases for online transaction processing (OLTP) and online analytical processing (OLAP).
Use of Indexes
Indexes are used by queries to find data from tables quickly. They are created on tables and views. The index on a table or a view is very similar to an index that found in a book. An index is a very important part of data content that helps to locate specific content.
Naming convention used: SP is used for the stored procedures, TBL is used for tables, and IX is used for indexes.
Consider the employee data table given below:
| ID | Name | Salary | Gender |
| 1 | James | 2500 | Male |
| 2 | Emily | 6500 | Female |
| 3 | David | 4500 | Male |
| 4 | Mia | 5500 | Female |
| 5 | Paul | 3100 | Female |
To create an index for the above table using any key in order to make it easier to read and avoid the scan process, the following code could be processed.
CREATE Index IX_tblEmployee_Salary
ON tblEmplyee (SALARY ASC)
Here, with the above code, you can create an index on the salary column. Hence, salary is the key here. The key values are arranged in ascending order with the code used. ASC stands for the ascending order of the key values. If the key values are to be arranged in descending order, then use the keyword DESC.
After the execution of the code, the table is indexed as per the key values in a predefined manner. Each row gets a row address after indexing.
The output would appear as shown below.
| Salary | Row Address |
| 2500 | Row Address |
| 3100 | Row Address |
| 4500 | Row Address |
| 5500 | Row Address |
| 6500 | Row Address |
The tag mentions the row addresses for each row. However, in actuality, they appear in a hexadecimal code.
The advantage of indexing is that the execution time reduces, and the desired result can be easily tracked. Thus, improved performance of the query can be eventually achieved.
Intermediate SQL data analysis
Intermediate SQL Analysis involves using SQL for data analysis using GROUP BY, HAVING, aggregate function, Date and Time functions and String functions.
GROUP BY
GROUP BY clause is used when one wants to form a group of data. Grouping can be done independent to each other.
Syntax: SELECT Select_list FROM Table_name GROUP BY column_name1, column_name2 ,...;
HAVING
The HAVING clause is often used with GROUP BY clause. When one wants to filter group based on some specified condition, HAVING clause is used with the GROUPBY clause.
Syntax: SELECT Select_list FROM Table_name GROUP BY group_list HAVING conditions;
Aggregate function
SQL has many built-in aggregate functions.
Some of the commonly used aggregate functions are listed below.
- COUNT-Counts the number of rows present in the table.
- SUM-Add all the values present in a particular column
- MIN and MAX- It returns the minimum and maximum value present in a particular column.
- AVG- Calculates the average of values present in a specific column.
Date and Time functions
To calculate data and time the following predefined function is used in SQL: SYSDATETIME() function
SYSDATETIME() function returns the current system date and time on which SQL server is running.
Syntax: SYSDATETIME()
String functions
String Functions in SQL takes a string as input, processes the input string and gives a string or numeric value as an output.
Few basic string functions are given below:
- ASCII- Returns the ascii value of the input
- CHAR- convert an ASCII input into its character value
- CONCAT- Join two or more strings together.
- LEN- Calculates the length of the input.
Subqueries
In SQL, a query can operate on the result set returned by another query. The resultset is generated by a subquery. A subquery is a query that is embedded in the WHERE clause of another SQL query.
Important rules for subqueries:
- The subquery can be used in various SQL clauses, including the WHERE, HAVING, and FROM clauses.
- With the expression operator, subqueries can be utilized with SELECT, UPDATE, INSERT, and DELETE statements. It could be an equality operator or a comparison operator like =, >, =, <=, and Like.
- A subquery is a query that is contained within a query. The outer query is the main query while the inner query is the subquery.
- The subquery is usually run first, and the results are utilized to complete the query condition for the main or outer query. A pair of parentheses must enclose the subquery.
- On the right-hand side of the comparison, the operator forms the subqueries.
- The ORDER BY clause cannot be used in a subquery. The GROUP BY clause performs the same function as the ORDER BY clause.
- With single-row subqueries, single-row operators can be used. With multiple-row subqueries multiple-row operators can be used.
Recursive Join
Recursive join is a relational database management system operation. Fixed point join is another name for it. It is a content process in which the join action is repeated; usually accumulating more records each time. When working with self-referential data or graph/tree-like data structures, recursive inquiries are useful. The following are a few instances of these scenarios:
Self-referential data:
- Manager -> Subordinate (employee) relationship
- Category -> Subcategory -> Product relationship
- Graphs — Flight (Plane Travel) map
In such cases, recursive join is useful.
Common Table Expression (CTE) is an SQL, which uses WITH clause, that is most typically used for simplifying exceedingly complex queries in recursive queries (subqueries). Let's have a look at an example:
WITH avg_salary AS (
SELECT avg(salary)
FROM employees
)
SELECT avg_salary;
Recursion is a highly strong tool that may be used to tackle various problems in a very elegant manner. It is not widely used with SQL. However, recursion can make your code less comprehensible. Therefore, use it carefully, particularly with SQL, which is sometimes difficult to digest and understand even without it.
Multiple Join
Data is stored in tables in relational databases. Without a doubt, and in most cases, it requires integrating data from multiple tables. The joins is used to integrate data from two or more tables, thereby allowing the access to data from several tables.
A query with multiple joins has the same or distinct join types that are used more than once. As a result, numerous tables of data can be combined to solve relational database problems.
As per the requirement of relational data, the tables could be joined using any of the four join operators which detailed below with their respective illustrations.
Inner Join
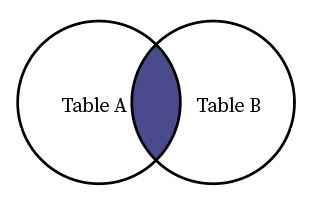
It returns as result the records which have matching values in both the tables.
Left Join
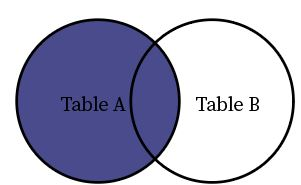
Left join returns all the rows in the left table (Table A) and matched rows from the right table (Table B).
Right Join
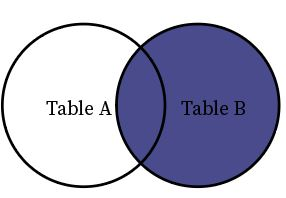
Right join returns all the rows from Table B and matched rows from Table A.
Full Join

All the rows from both the tables are returned along with the matched rows.
Advanced SQL
In case of a complex data set, intermediate SQL query is used and sometimes advanced query requests are raised. Hence, the study of SQL query can be categorized into three sections, namely beginner query, intermediate query, and advanced query. The beginner query is restricted to the understanding of clauses, concept, syntax, and the idea of various transactions that can be executed using SQL. On the other hand, for complex and advanced data set, intermediate or advanced SQL are used.
Take a look at the table below to understand the hierarchy of learning intermediate and advanced SQL function.
| Intermediate SQL | Advanced SQL |
| Concept of joins | Reads an execution plan and comprehends how the query's various sections affect it. |
| Pivots | Understands the data structure on the disk. |
| Monitoring/debugging | Monitors and manages database behavior. |
| Use of indexes | Uses performance counter function. |
| Use of triggers | Uses triggers with minimal risk function. |
| Understanding and applying transaction layer | Uses distributed transactions. |
Common Mistakes
While raising a query or designing a database, there are chances of using a function that does not suit the requirement and can return complex data. So, various practical problems may occur while using functions, selecting keys in an index, raising subqueries, conflict with user defined queries, and applying join to multiple tables for getting cross table data. These can be identified easily only when the execution of one process is verified.
-SQL query is case-sensitive. Use the appropriate commands.
-Use the GROUPBY clause after WHERE clause.
-Write the correct syntax for the correct output.
-While writing queries and subqueries keep the order in mind.
Context and Applications
This topic is significant in the professional exams for graduate and postgraduate courses,
especially:
- Bachelors in Computer Applications.
- Bachelors in Computer Science and Engineering.
- Masters in Computational Data Science.
- Masters in Computer Science Engineering.
Related Concepts
- MySQL.
- Subqueries.
- Cross table Query.
- Advanced Queries.
- Joins.
Practice Problems
Q1. Which of the following is used in SQL to get data from multiple tables?
(A) Subqueries
(B) Indexing
(C) Join
(D) None of the above
Correct Option: (C)
Explanation: Join clause in SQL is used to combine rows of two or more than two relations.
Q2. Which of the following is also known as fixed point join?
(A) Inner join
(B) Left join
(C) Full join
(D) Recursive join
Correct Option: (D)
Explanation: To obtain the parent-child data, we use recursive join. In SQL, recursive join was implemented using recursive common table expressions.
Q3. Index uses ……….. to sort data.
(A) functions
(B) keys
(C) joins
(D) None of the above
Correct Option: (B)
Explanation: Keys are a unique set of attributes which are used to identify the specific row in the table.
Q4. Recursive joins are used in which of the following?
(A) Relational database
(B) Distinct database
(C) Complex database
(D) None of the above
Correct Option: (A)
Explanation: Relational database is a set of database having predefined relationships among them.
Q5. The SQL engine is a system component that is used to CRUD data from a database. CRUD is an Abbreviation for:
(A) Create, read, update, and delete
(B) Cast, relate, update, and delete
(C) Create, relate, update, and delete
(D) None of the above
Correct Option: (A)
Explanation: CRUD stands for create,read,update and delete. These are the main CRUD operations.
Want more help with your computer science homework?
*Response times may vary by subject and question complexity. Median response time is 34 minutes for paid subscribers and may be longer for promotional offers.
Search. Solve. Succeed!
Study smarter access to millions of step-by step textbook solutions, our Q&A library, and AI powered Math Solver. Plus, you get 30 questions to ask an expert each month.
Intermediate SQL Concepts Homework Questions from Fellow Students
Browse our recently answered Intermediate SQL Concepts homework questions.
Search. Solve. Succeed!
Study smarter access to millions of step-by step textbook solutions, our Q&A library, and AI powered Math Solver. Plus, you get 30 questions to ask an expert each month.