What is Temporal difference learning?
Temporal difference learning (TD learning) is a concept in machine learning that attributes to a class of model-free reinforcement learning methods. The technique predicts a reward or quantity depending on the future values of the value function.
The name temporal difference is coined based on its use of changes or differences in predictions over successive time steps to drive the learning procedure. At any time step, the prediction is revised to drive it closer to the prediction of the same quantity in the following steps.
TD learning methods are also known as bootstrapping methods.
Temporal difference (TD) learning variants
TD(0) - The simplest form of TD learning
TD(0) learning is the simplest algorithm. It updates the value function with the value of the next state after every step. The reward is obtained in the process. The obtained reward is the key factor that keeps learning ground, and the algorithm converges after some sampling.
Mathematically, TD(0) learning can be expressed as follows:
V(St) = V(St) + α (Rt+1 + γ V(St+1) - V(St))
Here, α is the learning factor and γ is the discount factor. The value of state S updates in the next time step (t + 1) based on the reward Rt+1 observed after each time step t and destination from time step t + 1. This indicates it is the bootstrap of S at time step t with an estimation from time step t+1 while Rt+1 is the observed reward. Further, TD target and TD error (mentioned below) are two essential parts of the equation used in several parts of reinforcement learning (RL).
TD target = Rt+1 + γ V (St+1)
TD error (δ) = Rt+1 + γ V (St+1) - V(St)
TD-lambda (λ) learning
Gerald Tesauro used the TD-lambda learning algorithm to develop TD-Gammon, a program that learned to play backgammon games like human experts.
Lambda is the trace decay parameter, with 0 ≤ λ ≤1. Higher values will give longer traces. A larger proportion of credit from a reward can be yielded to provide more distant states and actions when λ is higher, with λ = 1 giving parallel learning to Monte-Carlo algorithms.
On-policy TD learning
On-policy TD learning algorithms learn the value of policies used for decision-making. The value functions are modified as per the results of executing actions given by some policy. Such policies are not strict. They are soft and non-deterministic. They select the action that gives the highest reward.
Off-policy learning
Off-policy TD learning algorithms are soft policies that learn policies for behavior and estimation. The algorithm updates the estimated value functions with hypothetical actions (actions that have not yet been tested). Off-policy learning methods can distinguish exploration from controls. Consequently, an agent trained with off-policy learning can learn tactics that they did not exhibit in the learning phase.
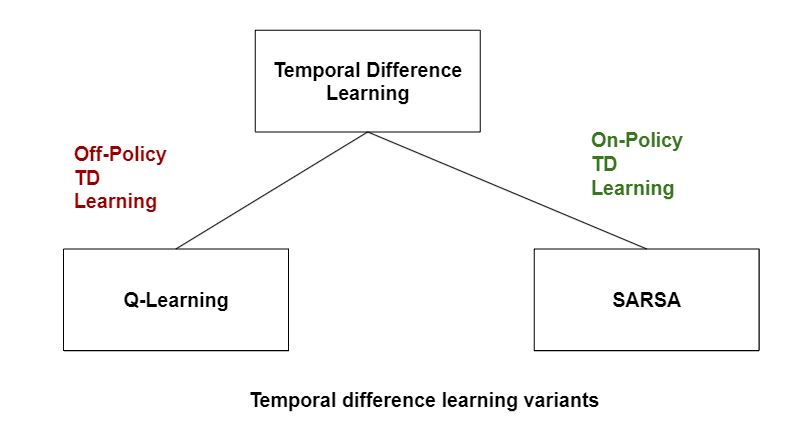
State-action-reward-state-action (SARSA)
SARSA is used in reinforcement learning to learn Markov decision process policy. A SARSA agent communicates with the environment and revises the policy based on the actions executed. Thus, it is an on-policy learning algorithm.
The main function for updating the Q-value in the SARSA algorithm is based on the current state of the agent S1, the action chosen by agent A1, the reward R the agent received for selecting the action, state S2 that the agent enters after taking the action, and the next action A2 that the agent selects in the new state. The tuple representing the above statement is (st, at, rt, st+1, at+1) and is called SARSA.
The SARSA algorithm is represented as follows:
Q(St, at) = (St, at) + α [rt + γ Q (St+1, αt+1) - Q(St, at)]
Here, the Q value for the state-action is updated by an error, adjusted by the learning rate α. Q shows the reward signal obtained in the next time step to take any action in a state S in the discounted future reward from the next-state action observation. SARSA learns the Q values based on the policy that it follows itself.
Q-learning
Q-learning is an off-policy learning algorithm in reinforcement learning. It strives to determine the action to be taken for the current state. It maximizes the reward by learning from the actions that are not included in the present policy. It does not utilize an environment. It can handle stochastic transitions and rewards without adaptations.
Temporal difference learning in neuroscience
Temporal-difference learning is also linked with the neuroscience field. Researchers claim that the firing rate of dopamine neurons in the ventral tegmental area and substantia nigra is similar to the error function in the TD algorithm. The error function returns the difference between the predicted and actual reward at each time step. If the error function is huge, the difference is also huge. If this is combined with a stimulus that depicts the future reward, the error can relate the stimulus with the future reward. Dopamine cells work on the same concept.
This observation has encouraged neuroscientific and computational research based on the TD learning computation theory. The theory helps understand the brain’s dopamine system and its role in drug addiction. It also assists in studying situations like schizophrenia.
Temporal difference learning advantages
Temporal-difference learning methods have the following advantages:
- Temporal differences can be learned in every step, online or offline.
- Temporal difference methods can be learned from incomplete sequences.
- Temporal difference methods can function in non-terminating environments.
- Temporal difference learning has a lower variance than Monte Carlo.
- Temporal difference learning is more efficient than Monte Carlo learning.
- Temporal difference learning exploits the Markov property. It is more effective than Markov environments.
Temporal difference learning disadvantages
Though TD learning is effective and efficient than other learning algorithms, it has the following limitations:
- Temporal difference learning is a biased estimation.
- It is more sensitive to the starting value.
Context and Applications
Temporal difference learning is a significant topic for students studying courses such as:
- Bachelors in Engineering (Machine Learning)
- Certification in Data Science
- Masters in Business Administration (Business Analytics)
- Masters in Machine Learning
Practice Problems
1. Which of these are the types of machine learning?
- Supervised learning
- Unsupervised learning
- Reinforcement learning
- All of these
Answer: Option d
Explanation: In machine learning, there are mainly three types of learning algorithms: supervised learning, unsupervised learning, and reinforcement learning.
2. In which type of learning does the teacher return reward and punishment to the learner?
- Reinforcement learning
- Connectionism learning
- Prediction problems learning
- Action-value learning
Answer: Option a
Explanation: According to the definition, the teacher returns reward and punishment to the learner in reinforcement learning.
3. Which type of algorithms learns policies for behavior?
- Off-policy
- On-policy
- Prediction problems
- Temporal-difference
Answer: Option a
Explanation: The off-policy TD learning algorithms learn policies for behavior and estimation.
4. Which of these algorithms is an on-policy algorithm?
- Q-learning
- SARSA
- Monte Carlo
- Connectionist
Answer: Option b
Explanation: The SARSA algorithm updates results based on the decisions or actions taken. It follows on-policy learning methods.
5. What type of reinforcement learning is a temporal-difference learning method?
- Model-free
- Model-based
- Prediction-problems based
- Eligibility traces free
Answer: Option a
Explanation: TD learning is classified as a model-free reinforcement method. It predicts a reward based on future values.
Common Mistakes
Students should understand the difference between Q-learning, temporal difference learning, and SARSA since they are all different types of reinforcement learning methods.
Related Concepts
- Rescorla-Wagner model
- Reinforcement learning
- Game theory
- Eligibility traces and TD algorithms
- Monte Carlo learning
Want more help with your computer science homework?
*Response times may vary by subject and question complexity. Median response time is 34 minutes for paid subscribers and may be longer for promotional offers.
Search. Solve. Succeed!
Study smarter access to millions of step-by step textbook solutions, our Q&A library, and AI powered Math Solver. Plus, you get 30 questions to ask an expert each month.
Artificial Intelligence
Reinforcement Learning
Temporal Difference Learning
Temporal difference learning Homework Questions from Fellow Students
Browse our recently answered Temporal difference learning homework questions.
Search. Solve. Succeed!
Study smarter access to millions of step-by step textbook solutions, our Q&A library, and AI powered Math Solver. Plus, you get 30 questions to ask an expert each month.