
Computer Networking: A Top-Down Approach (7th Edition)
7th Edition
ISBN: 9780133594140
Author: James Kurose, Keith Ross
Publisher: PEARSON
expand_more
expand_more
format_list_bulleted
Related questions
Question
TODO 1: To generate a statistical summary for each of our numerical attributes, use the Pandas DataFrame describe() function on our forestfire_df.
# TODO 1
ff_describe =
display(ff_describe)
todo_check([
(ff_describe.shape == (8,11),'ff_describe shape did not match (8, 11)'),
(np.all(np.isclose(ff_describe.values[:4,2:4].flatten(), np.array([517. ,517. ,90.64468085,110.87234043,5.52011085,64.04648225,18.7,1.1]),rtol=.01)),'The values of ff_describe were wrong!'),
])
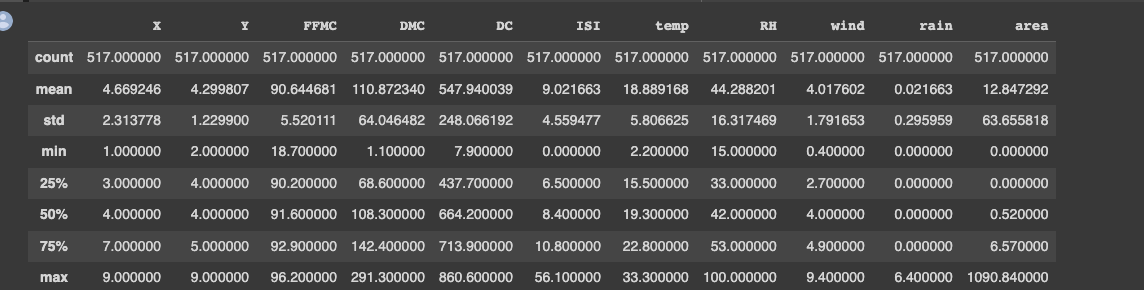

Transcribed Image Text:The table provides a statistical summary of data related to a dataset, likely concerning environmental or meteorological factors, as indicated by the column headers. Here is a detailed breakdown of each column:
- **X and Y**: Coordinates relating to the geographical location. Each has 517 data points, with similar statistics:
- Mean: X is 4.669 and Y is 4.299
- Standard Deviation (std): X is 2.314 and Y is 1.230
- Minimum: X is 1, Y is 2
- Maximum: X is 9, Y is 9
- **FFMC (Fine Fuel Moisture Code)**: Reflects moisture content of litter fuels and has 517 entries.
- Mean: 90.645
- Std: 5.520
- Min: 18.7
- 25% percentile: 90.2
- 50% percentile (Median): 91.6
- 75% percentile: 92.9
- Max: 96.2
- **DMC (Duff Moisture Code)**: Indicates moisture level in loosely compacted organic layers.
- Mean: 110.872
- Std: 64.046
- Min: 1.1
- **DC (Drought Code)**: Represents soil moisture affecting vegetation.
- Mean: 547.940
- Std: 248.066
- Min: 7.9
- **ISI (Initial Spread Index)**: Index predicting fire spread.
- Mean: 9.022
- Std: 4.559
- Min: 0.0
- **Temp (Temperature in Celsius)**:
- Mean: 18.889
- Std: 5.807
- Range: 2.2 to 33.3
- **RH (Relative Humidity in percentage)**:
- Mean: 44.288
- Std: 16.317
- Range: 15 to 100
- **Wind (Wind speed in km/h)**:
- Mean: 4.018
- Std: 1.792
- Range: 0.4 to 9.4
- **Rain (Rain in mm)**:
- Mean
Expert Solution
This question has been solved!
Explore an expertly crafted, step-by-step solution for a thorough understanding of key concepts.

Step by stepSolved in 4 steps with 3 images

Knowledge Booster

Similar questions
- 1. Calculate the Model Precision and Recall Write a function from scratch called prec_recall_score() that accepts as input (in this exact order): a list of true labels a list of model predictions This function should compute and return both the model precision and recall (in that order). Do not use the built-in Scikit-Learn functions precision_score(),recall_score(), confusion_matrix(), or Panda's crosstab() to do this. Instead, you may use those functions after to verify your calculations. We want to ensure that you understand what is going on behind-the-scenes of the precision and recall functions by creating similar ones from scratch.arrow_forwardNumpyarrow_forwardPlease answer them in R thank you.arrow_forward
- 7. group_friends_by_food For this problem, you are given a mostly-working version of the Friend and FriendsDB classes from hw6 and hw7, and we will add new method to FriendsDB -- group_friends_by_food. group_friends_by_food returns a dictionary mapping from each of the favorite foods enjoyed by any friend to a list of the friends who enjoy that food, sorted in alphabetical order. (You can use the friends_who_love method to generate these lists.) A sample run should look like this: |>>> friend1 = Friend ("sarah", 165) >>> friend1.add_favorite_food ("strawberries") >>> friend2 - Friend ("dweezil", 175) >>> friend2.add_favorite_food("pizza") >>> friend3 = Friend("bimmy", 60) >>> friend3.add_favorite_food("pizza") >>> friend3.add_favorite_food("strawberries") >>> db = FriendsDB() >>> db.add friend (friend1) >>> db.add_friend(friend2) >>> db.add friend(friend3) >>> db.group_friends_by_food() {'strawberries': ['bimmy', 'sarah'], 'pizza': [' bimmy', 'dweezil']}arrow_forwardHeres what I have roster = {}for i in range(5):jersey_number = int(input(f"Enter player{i+1}'s jersey number:\n"))rating = int(input(f"Enter player{i+1}'s rating:\n"))roster[jersey_number] = ratingsorted_keys = sorted(roster.keys())print("ROSTER")for key in sorted_keys:print(f"Jersey number:{key}, Rating:{roster[key]}")menu = "MENU\na - Add player\nd - Remove player\nu - Update player rating\nr - Output players above a rating\no - Output roster\nq - Quit\n"while True:print(menu)option = input("Choose an option:\n")if option == "a":jersey_number = int(input("Enter a new player's jersey number:"))rating = int(input("Enter the player's rating:\n"))roster[jersey_number] = ratingelif option == "d":jersey_number = int(input("Enter a jersey number: "))if jersey_number in roster:del roster[jersey_number]else:print("Jersey number not found.")elif option == "u":jersey_number = int(input("Enter a jersey number:\n"))if jersey_number in roster:rating = int(input("Enter a new rating for…arrow_forwardSeq is a sequence object that can be imported from Biopython using the following statement: from Bio.Seq import Seq If my_seq is a Seq object, what is the correct Biopython code to print the reverse complement of my_seq? Hint. Use the built-in function help you find out the methods of the Seq object. print('reverse complement is %s' % complement(my_seq.reverse())) print('reverse complement is %s' % my_seq.reverse()) print('reverse complement is %s' % my_seq.reverse_complement()) print('reverse complement is %s' % reverse(my_seq.complement()))arrow_forward
- Write a struct ‘Student’ that has member variables: (string) first name, (int) age and (double) fee. Create a sorted (in ascending order according to the age) linked list of three instances of the struct Student. The age of the students must be 21, 24 and 27. Write a function to insert the new instances (elements of the linked list), and insert three instance whose member variable have age (i) 20, (ii) 23 and (iii) 29. Write a function to remove the instances from the linked list, and remove the instances whose member variables have age (i) 21 and (ii) 29. Write a function to count the elements of the linked list. Write a function to search the elements from the linked list, and implement the function to search an element whose age is 23. Write a function to print the linked list on the console. Consider the Student struct as defined above. Create a stack of 5objects of the class. Implement the following (i) push an element to the stack (ii) pop an element from the stack (iii) get the…arrow_forwardThe shape class variable is used to save the shape of the forestfire_df dataframe. Save the result to ff_shape. # TODO 1.1 ff_shape = print(f'The forest fire dataset shape is: {ff_shape}') todo_check([ (ff_shape == (517,13),'The shape recieved for ff_shape did not match the shape (517, 13)') ])arrow_forwardComplete the docstring using the information attached (images):def upgrade_stations(threshold: int, num_bikes: int, stations: List["Station"]) -> int: """Modify each station in stations that has a capacity that is less than threshold by adding num_bikes to the capacity and bikes available counts. Modify each station at most once. Return the total number of bikes that were added to the bike share network. Precondition: num_bikes >= 0 >>> handout_copy = [HANDOUT_STATIONS[0][:], HANDOUT_STATIONS[1][:]] >>> upgrade_stations(25, 5, handout_copy) 5 >>> handout_copy[0] == HANDOUT_STATIONS[0] True >>> handout_copy[1] == [7001, 'Lower Jarvis St SMART / The Esplanade', \ 43.647992, -79.370907, 20, 10, 10] True """arrow_forward
- TODO 12 Let's now split our input data X and labels y into a train and test set using the train_test_split() function (docs). Here we'll use the 80-20 split rule where we use 80% of the data for training and 20% for testing. Lastly, we'll seed our split using the random_state keyword argument which will make sure we create the same split every time we run the function. Use the train_test_split() function to get a train and test split. Store the output into X_train, X_test, y_train, and y_test. Pass the required arguments X and y. Further specify we want to use 20% of the training data by setting the test_size keyword argument. Lastly, pass the keyword argument random_state=42 to set the random seed so we get the same split every time we run this code. Print the shape for X_train. Print the shape for y_train. Print the shape for X_test. Print the shape for y_test. # TODO 12.1X_train, X_test, y_train, y_test = todo_check([ (X_train.shape == (413, 29), 'X_train does not have the…arrow_forwardUse an appropriate scikit-learn library we used in class to create y_train, y_test, X_train and X_test by splitting the data into 70% train and 30% test datasets. Set random_state to 4 and stratify the subsamples so that train and test datasets have roughly equal proportions of the target's class labels Standardise the data using StandardScaler libraryarrow_forwardIn Checkpoint B, the game will be playable as a two-player game, albeit the competition will be a computer player who makes moves randomly. Implement these functions from the template following the description (specification) in their docstring: shuffle() replace_deck() deal_initial_hands() play_hand() should be extended to support 'random' mode The main function to drive the game has been provided. In 'interactive' mode, play_hand() should behave the same way as in Part A In 'random' mode, the computer selects actions randomly. Compared to 'interactive' mode: Every call to input() for the player should be replaced with a random choice Extra printed feedback for the player should be omitted For testing, we have hard-coded the seed 26 for the random source Hint: you can use random.randint(x, y) to select a number between x and y, inclusive. In particular, "flipping a coin" would be accomplished via random.randint(0, 1) Sample input/output When the inputs are: yes 1 no yes 9 The…arrow_forward
arrow_back_ios
SEE MORE QUESTIONS
arrow_forward_ios
Recommended textbooks for you
- Computer Networking: A Top-Down Approach (7th Edi...Computer EngineeringISBN:9780133594140Author:James Kurose, Keith RossPublisher:PEARSON
 Computer Organization and Design MIPS Edition, Fi...Computer EngineeringISBN:9780124077263Author:David A. Patterson, John L. HennessyPublisher:Elsevier Science
Computer Organization and Design MIPS Edition, Fi...Computer EngineeringISBN:9780124077263Author:David A. Patterson, John L. HennessyPublisher:Elsevier Science Network+ Guide to Networks (MindTap Course List)Computer EngineeringISBN:9781337569330Author:Jill West, Tamara Dean, Jean AndrewsPublisher:Cengage Learning
Network+ Guide to Networks (MindTap Course List)Computer EngineeringISBN:9781337569330Author:Jill West, Tamara Dean, Jean AndrewsPublisher:Cengage Learning  Concepts of Database ManagementComputer EngineeringISBN:9781337093422Author:Joy L. Starks, Philip J. Pratt, Mary Z. LastPublisher:Cengage Learning
Concepts of Database ManagementComputer EngineeringISBN:9781337093422Author:Joy L. Starks, Philip J. Pratt, Mary Z. LastPublisher:Cengage Learning Prelude to ProgrammingComputer EngineeringISBN:9780133750423Author:VENIT, StewartPublisher:Pearson Education
Prelude to ProgrammingComputer EngineeringISBN:9780133750423Author:VENIT, StewartPublisher:Pearson Education Sc Business Data Communications and Networking, T...Computer EngineeringISBN:9781119368830Author:FITZGERALDPublisher:WILEY
Sc Business Data Communications and Networking, T...Computer EngineeringISBN:9781119368830Author:FITZGERALDPublisher:WILEY
Computer Networking: A Top-Down Approach (7th Edi...
Computer Engineering
ISBN:9780133594140
Author:James Kurose, Keith Ross
Publisher:PEARSON
Computer Organization and Design MIPS Edition, Fi...
Computer Engineering
ISBN:9780124077263
Author:David A. Patterson, John L. Hennessy
Publisher:Elsevier Science
Network+ Guide to Networks (MindTap Course List)
Computer Engineering
ISBN:9781337569330
Author:Jill West, Tamara Dean, Jean Andrews
Publisher:Cengage Learning
Concepts of Database Management
Computer Engineering
ISBN:9781337093422
Author:Joy L. Starks, Philip J. Pratt, Mary Z. Last
Publisher:Cengage Learning
Prelude to Programming
Computer Engineering
ISBN:9780133750423
Author:VENIT, Stewart
Publisher:Pearson Education
Sc Business Data Communications and Networking, T...
Computer Engineering
ISBN:9781119368830
Author:FITZGERALD
Publisher:WILEY